
Dirbuster
DirBuster is a multi threaded java application designed to brute force directories and files names on web/application servers. Often is the case now of what looks like a web server in a state of default installation is actually not, and has pages and applications hidden within. DirBuster attempts to find these. DirBuster searches for hidden pages and directories on a web server. Sometimes developers will leave a page accessible, but unlinked. DirBuster is meant to find these potential vulnerabilities. This is a Java application developed by OWASP.
1) Start with the terminal
One can start DirBuster with the terminal by typing:
dirbuster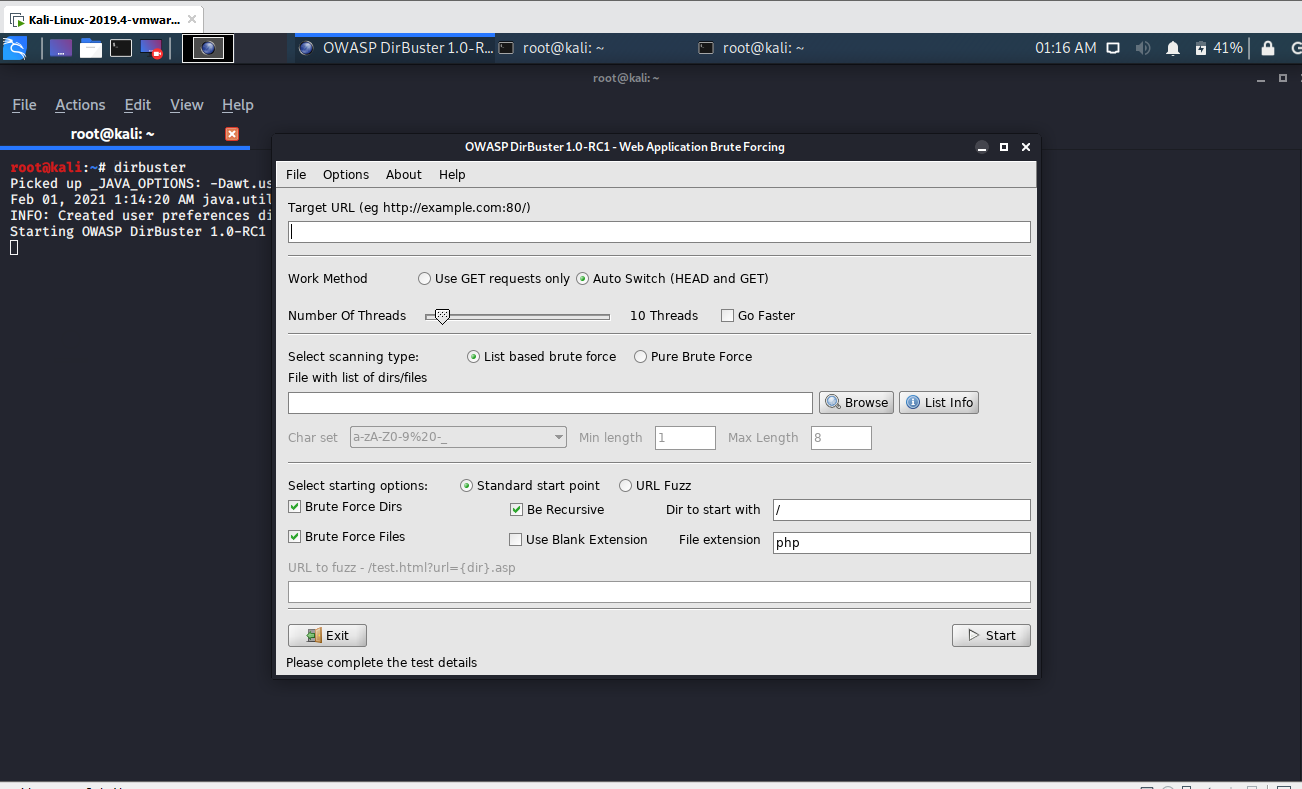
2) Set target URL and number of Threads
One will need obviously to provide the URL or IP address of the website from which you want more information, this URL needs to specify the port in which you want to specify the scan. The port 80 is the primary port used by the world wide web (www) system. Web servers open this port then listen for incoming connections from web browsers.
To specify the port 80 in the URL, you just need to add “double point and the number of the port at the end of the URL.
The number of threads that will be used to execute the brute forcing depends totally on the hardware of your computer.
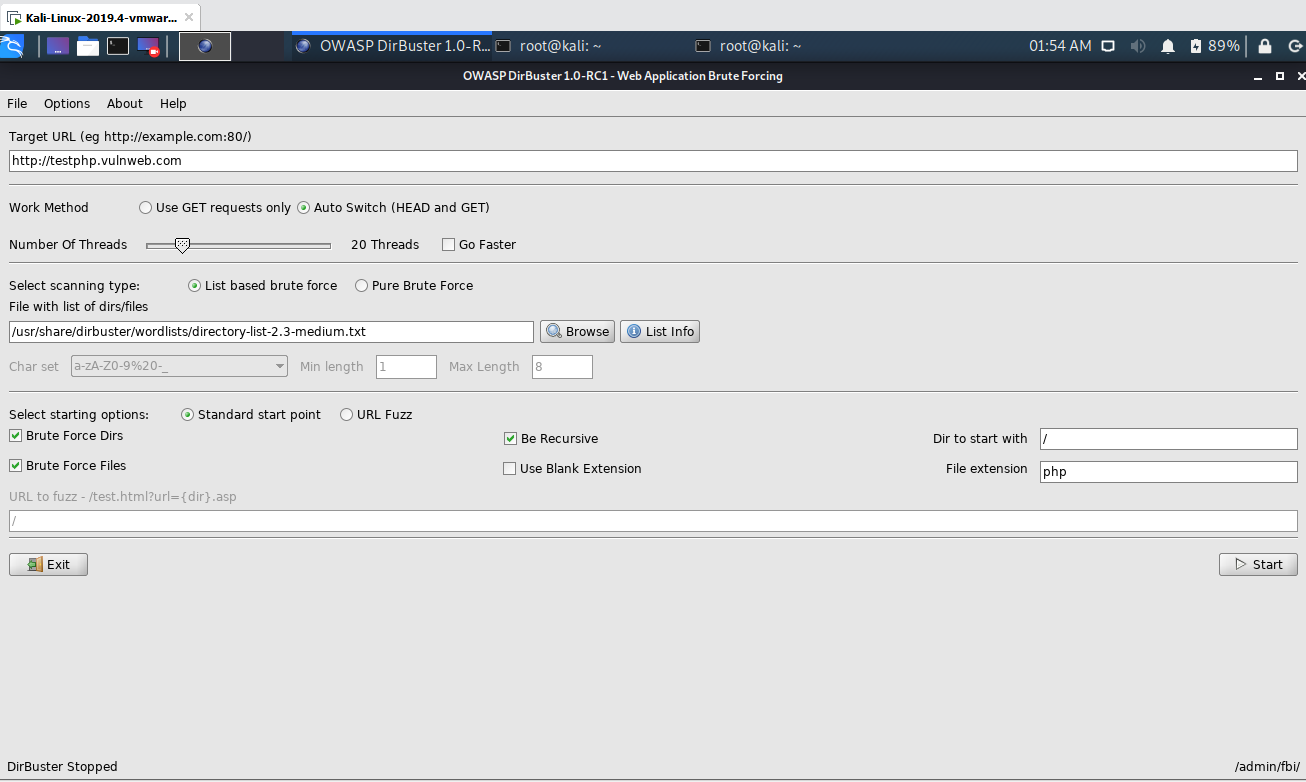
3) Select list of possible directories and files
As mentioned previously, DirBuster needs a list of words to start a brute force scan. you don’t need to make your own list or necessarily search for a list in Internet as DirBuster has already a couple of important and useful lists that can be used for your attack. Just click on the Browser button and selected the wordlist file (they’re normally located at /usr/share/dirbuster/wordlists) that you want to use for the brute force scan:
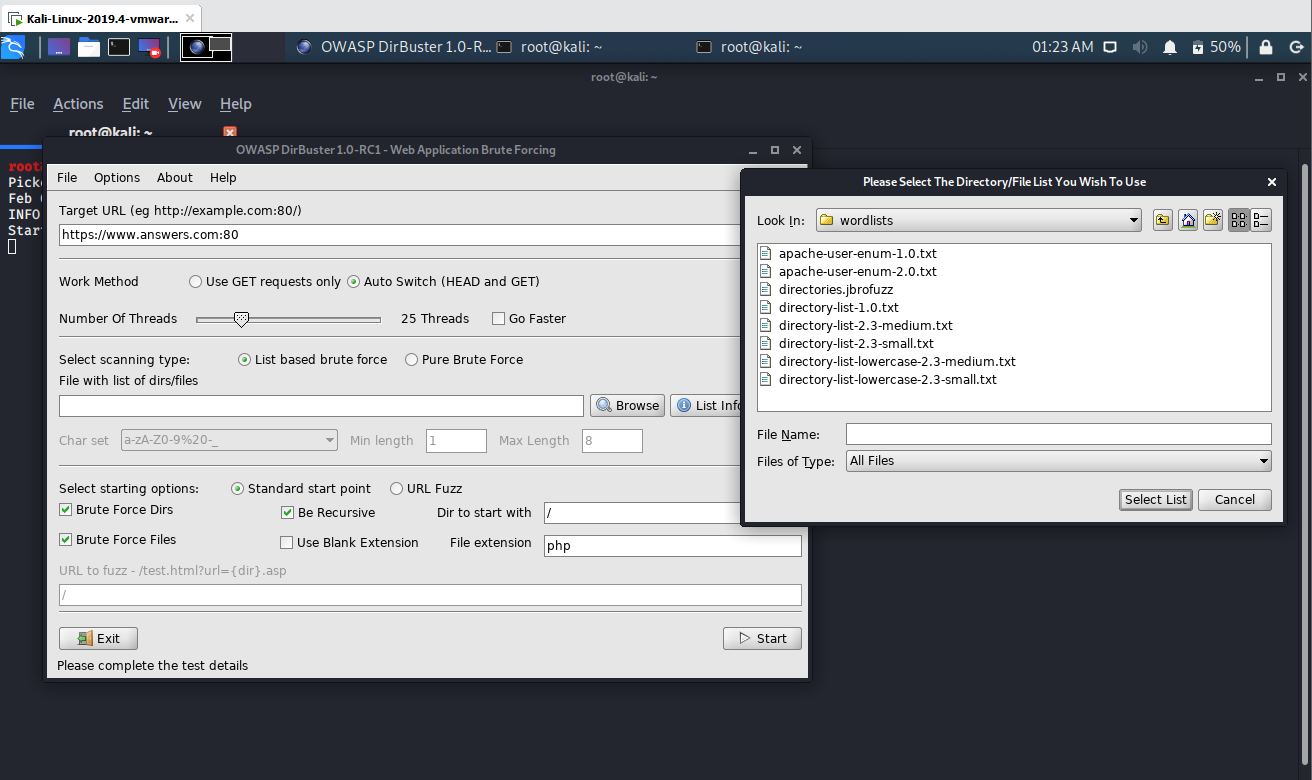
In this case we are going to use the directory-list-2.3-medium.txt file
4) Start brute force scan
To start the scan on the website, just press the Start button in the GUI. In this step DirBuster will attempt to find hidden pages/directories and directories within the provided url, thus giving a another attack vector.
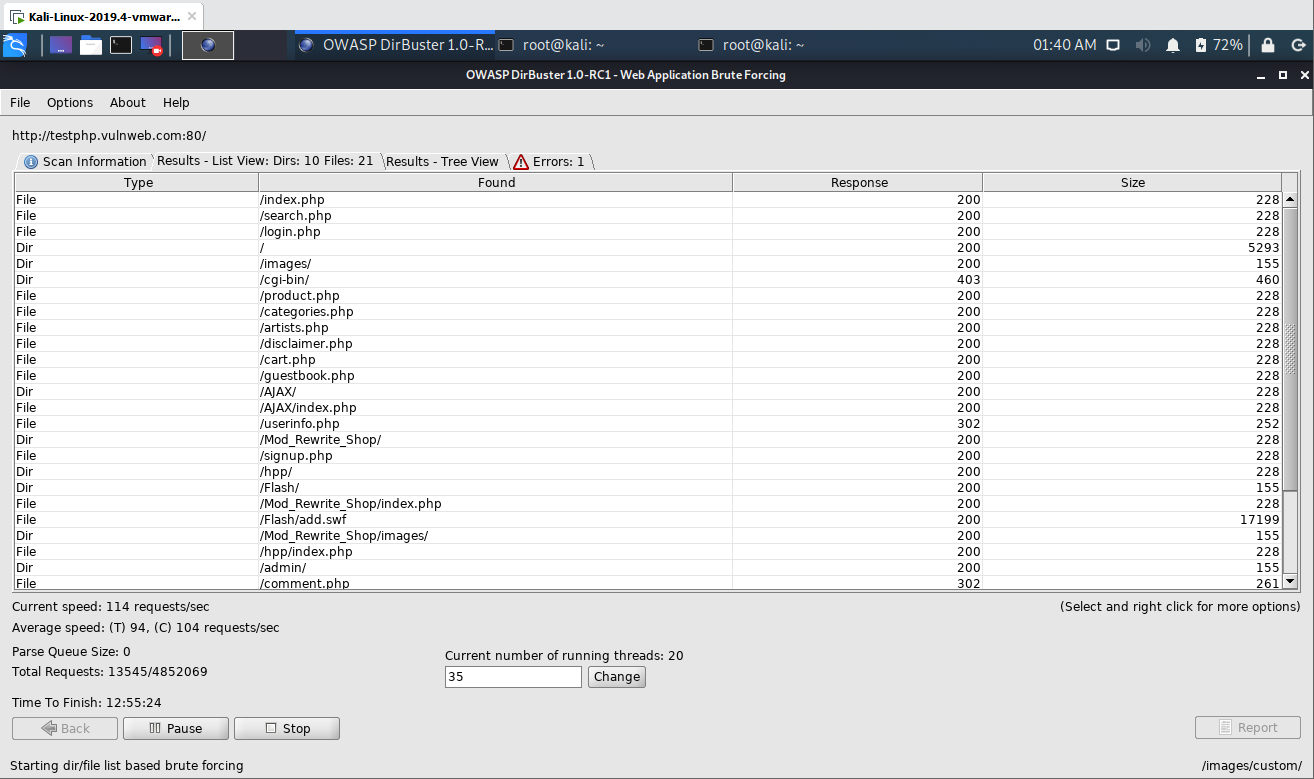
Tree view
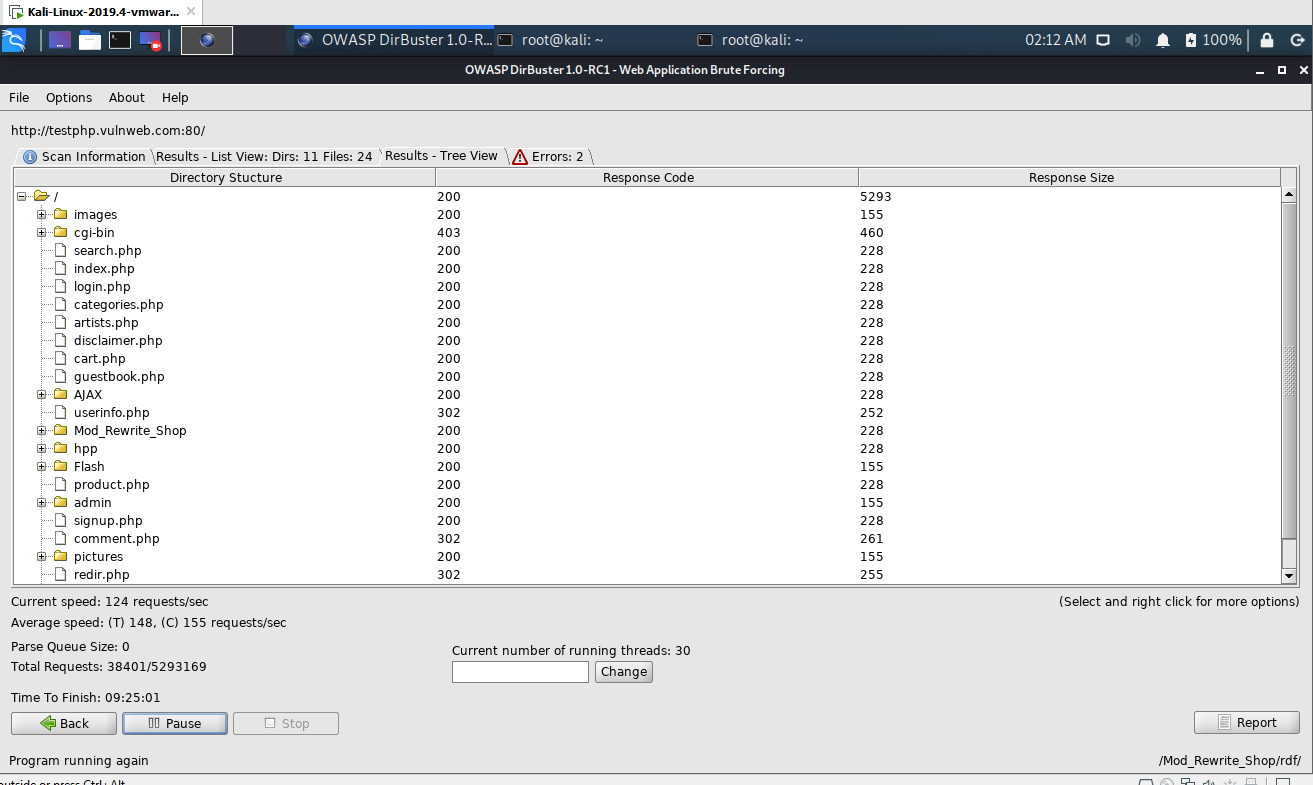
5) Generate report
Once the scan finishes (or you stop it) the Report button (disabled while the scan runs) will be enabled. With the report window you can export the scanned urls of the found directories and files into different formats as plain text, xml or csv. Just fill the form and then click on Generate report:
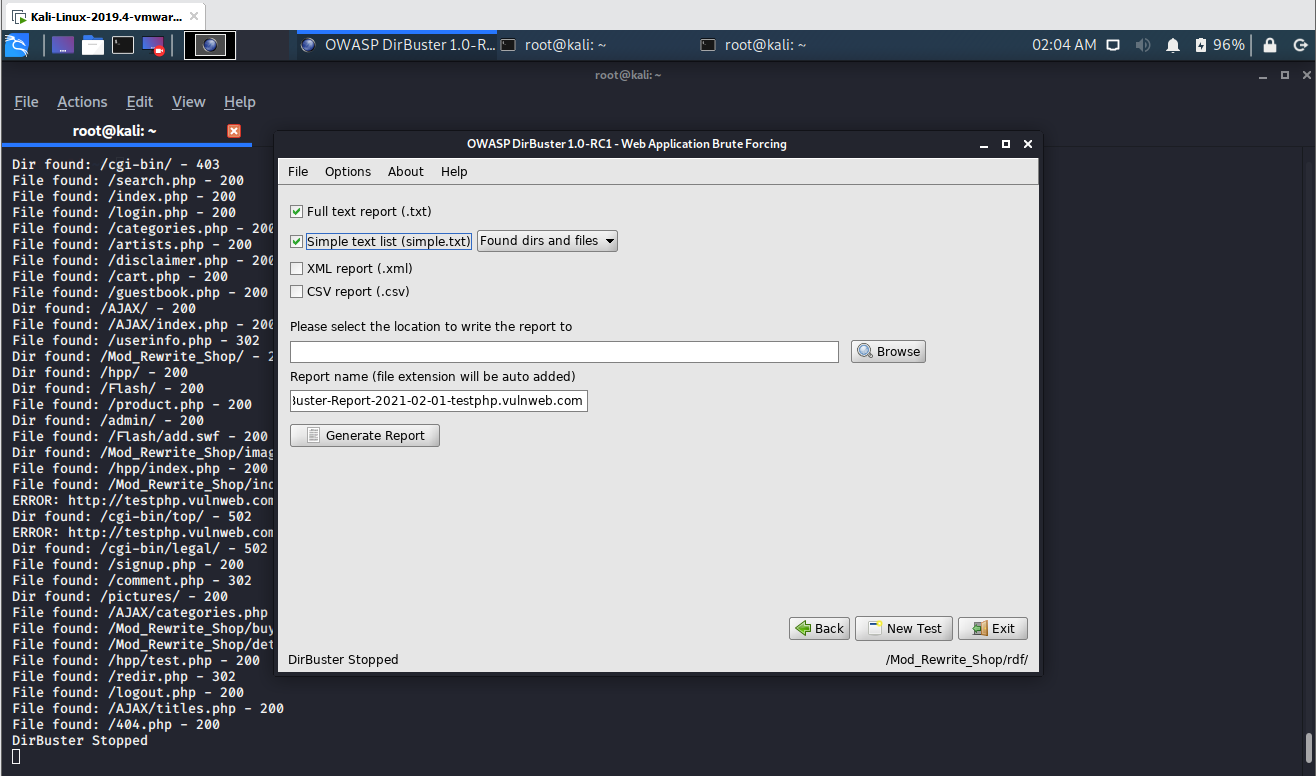
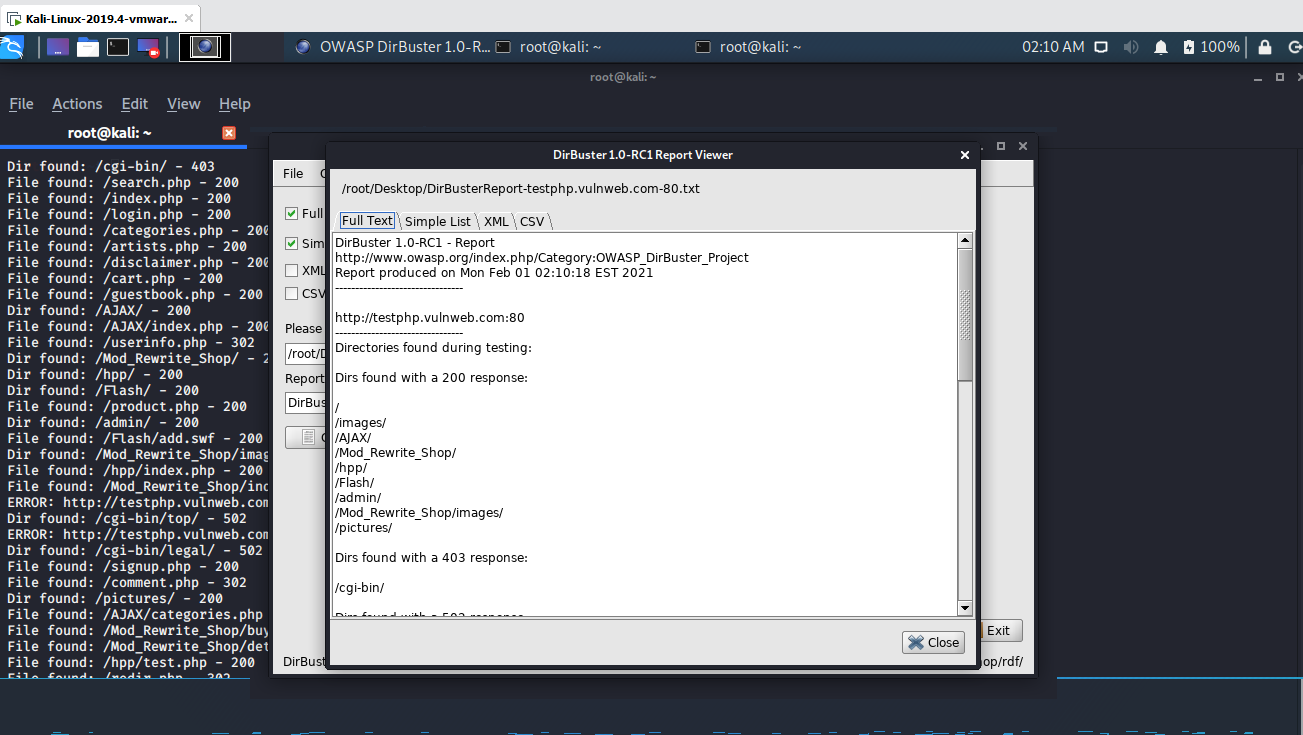
One can use this list for example to write some kind of scraper with Python or another language of your preference and then download all the available webpages of the scanned website.